


How we use AI to build a developer-first culture
08 Sep 2025
By: Shubhomoy Biswas, Cloud Engineer at Scania

Within our team, my responsibilities have included the design and implementation of our backend cloud infrastructure, as well as the establishment of the Continuous Integration and Continuous Deployment (CICD) pipeline for our microservices. It can often be a tedious endeavour to incorporate modifications into our infrastructure and align our CICD processes accordingly.
Infrastructure as Code (IaC) comes with a range of benefits, one of which is the convenience of maintenance. In light of this, we embarked on a mission. This involved either reworking the IaC for our existing AWS infrastructure that was initially set up manually, or creating IaC right from the beginning for any new resources or infrastructure desig
I will now share with you, one of the interesting findings and a hidden benefit of IaC me and my team discovered along the way.
Concerning the working methods of developers, at a broad level, we generally proceed through the following process.
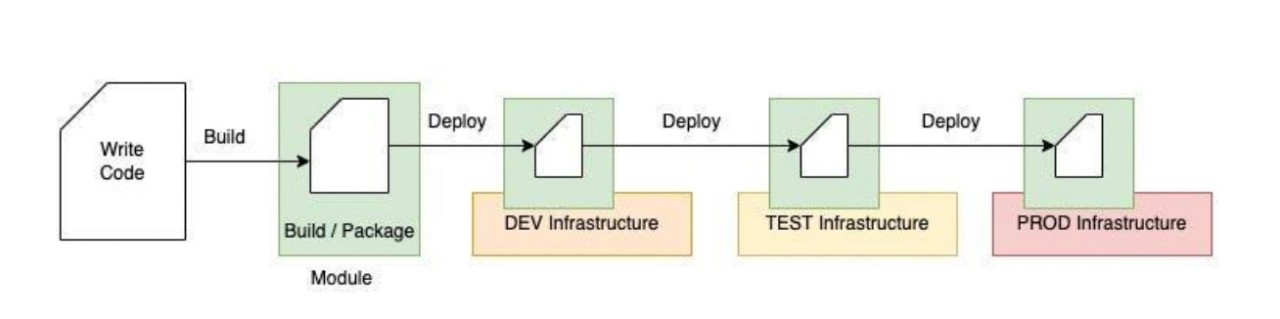
We employ version control systems like GIT to manage and implement our modules within the underlying infrastructure. After accomplishing this, we recognized that…
our microservices are deployed on either the same or shared
cloud resources.
For instance, consider two developers who are simultaneously working on distinct features of a module meant to be deployed as an AWS lambda function. The Continuous Integration/Continuous Deployment (CICD) processes in their respective pipelines will deploy the identical lambda function (a single resource in AWS), inadvertently overwriting each other’s contributions.
Based on my personal experience, this situation arises because we utilize a common AWS account during our development phase.
Nonetheless, to segregate diverse infrastructures, we establish different environments like DEV, TEST, PRE-PROD, PROD, and so forth.
However, the DEV environment stands apart. It must be shared among all team developers, which presents a quandary. When two developers collaborate on the same module but tackle different features, there’s a consistent risk of their modifications conflicting and overwriting each other’s work when changes are pushed to the DEV environment.
Hence, despite having their codebase versioned and segmented within GIT, the actual deployment lacks such isolation.
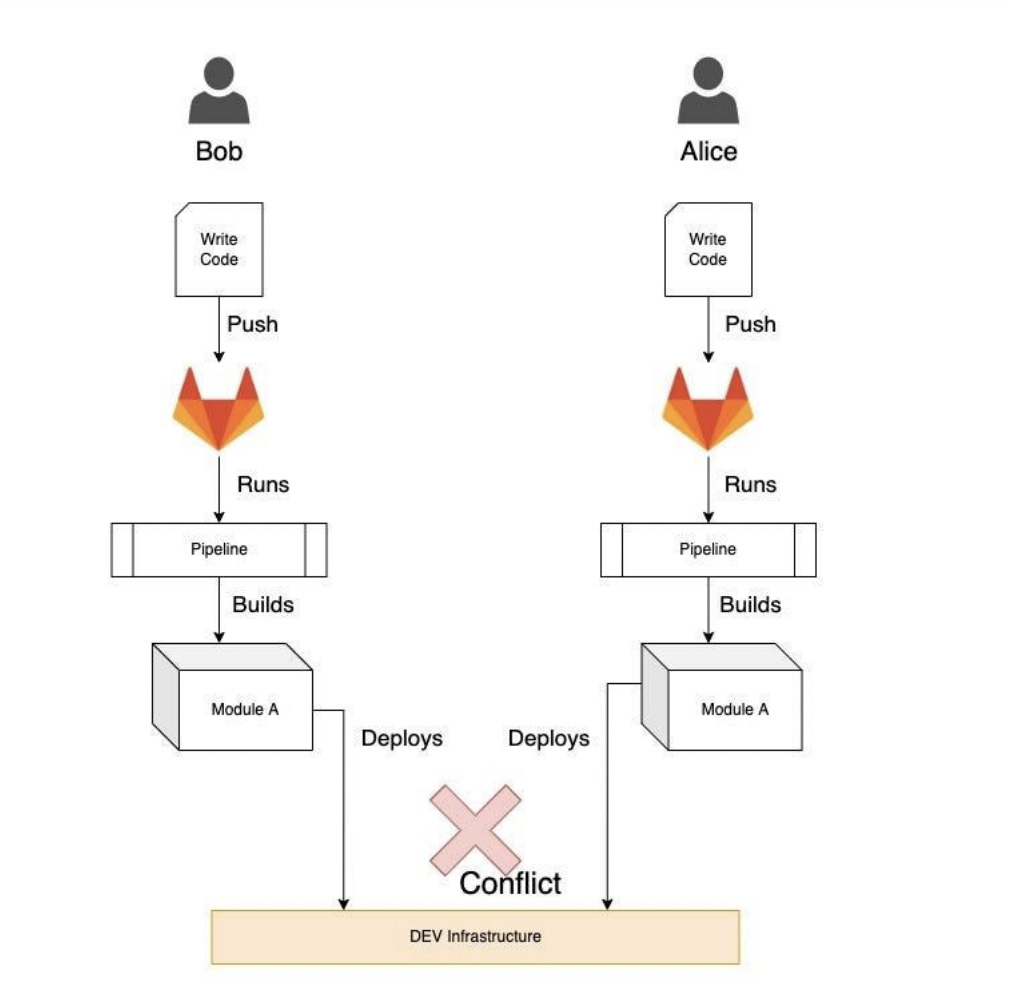
This situation becomes problematic when there is overlapping work required on the identical module or as the team expands.
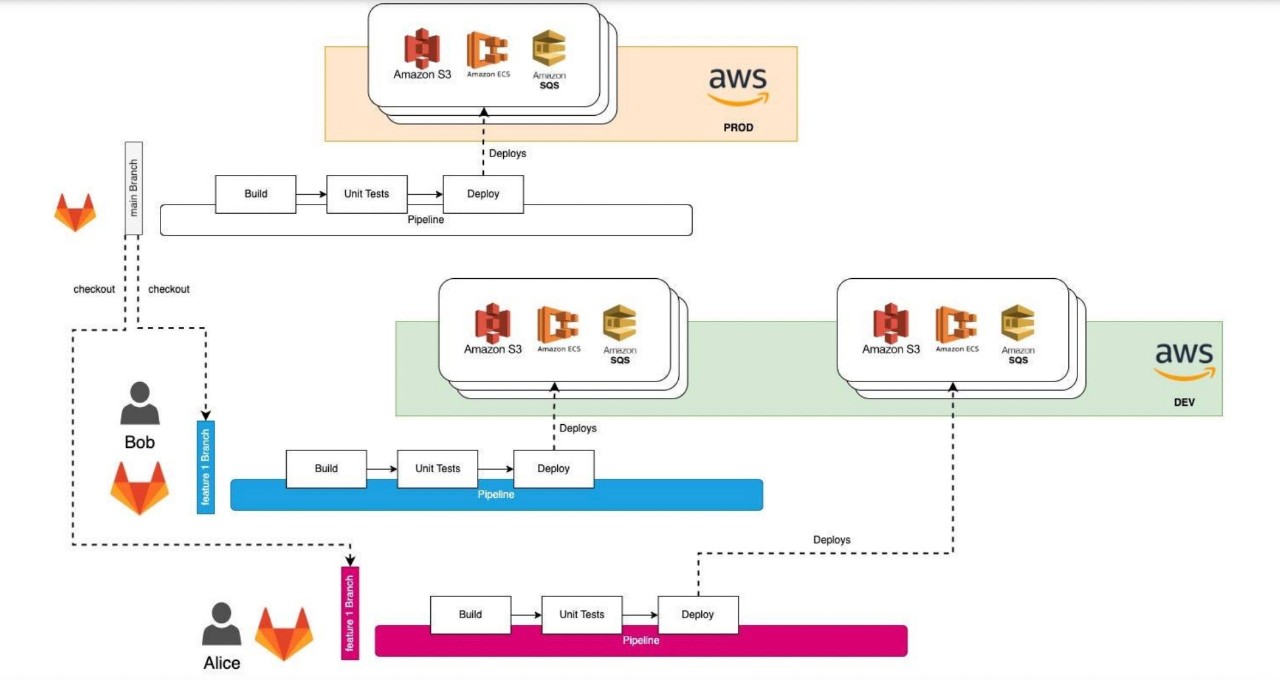
This is where one of the advantages of implementing infrastructure as code from the very beginning becomes apparent. We have the capability to replicate multiple environments for individual feature branches by setting up entirely new underlying infrastructures for each case. The CICD process associated with that branch will always reference specific cloud resources. As a result, every developer will have their dedicated development environment within the same cloud account. Moreover, the CICD should also have the functionality to decommission the infrastructure when the corresponding feature branch in GIT is merged or deleted.
In order to achieve something like this, we needed to get the following things defined and created.
• Naming Convention
We established an appropriate naming guideline to be applied to all our resources. Additionally, it was essential to ensure that the resource names remain exclusive to the respective feature branches. This was successfully accomplished by simply adding -XXX to the names, with XXX representing the feature branch identifier. Furthermore, we adhered to the practice of generating a feature branch in accordance with the JIRA ticket ID. This approach is critical as it guarantees distinct names for all our resources in alignment with the developers’ git branches.
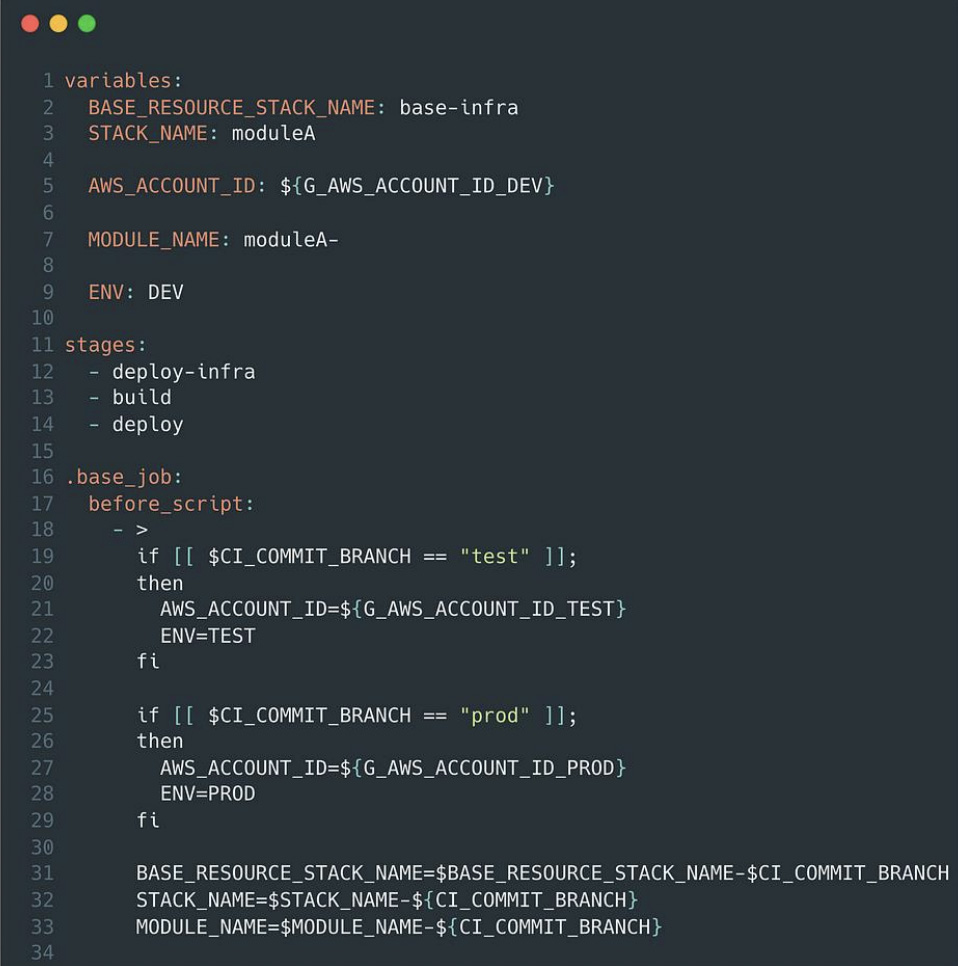
• Common base job
Within GITLAB, we established a base GITLAB job that accurately structures all necessary names in accordance with the commit branch name. This involves the previously mentioned process of adding the commit branch name to all resource names, along with additional preparatory actions such as converting to lowercase or uppercase. This strategy eliminates the need to repeatedly include the same preprocessing code in every defined GITLAB job, offering efficiency and consistency.
CloudFormation
The advantages of employing CloudFormation as our Infrastructure as Code solution in our scenario were as follows:
• We are relieved from the burden of managing the underlying state files.
• CloudFormation inherently ensures the isolation of infrastructure states by allowing us to specify distinct stack names.
With these benefits in mind, we could proceed to deploy CloudFormation stacks for each GIT branch. Given that we had already assigned unique names to AWS resources, conflicts between CloudFormation stacks were avoided.
Costs can escalate due to the approach outlined above, where we create numerous instances of identical cloud resources for each branch. Nonetheless, there is room for improvement in refining this optimization process.
• Separating out the base/core resources
Distinguish the fundamental resources and isolate them into distinct CloudFormation stack(s). These core resources will lack the previously mentioned -XXX suffixes. Core resources encompass those where developers’ code isn’t directly implemented. These could include ECS Clusters, OpenSearch instances, or any managed AWS services. We deploy these resources on separate stacks and export the necessary values that are required by other dynamically created stacks discussed above. To illustrate, in our scenario, we set up an ECS Cluster as a core resource, and the necessary Task Definitions are specified in dynamic stacks (having -XXX suffix in them) that are deployed as Tasks and/or Services on this shared ECS Cluster.
• Vacuuming orphaned resources
Ensuring the removal of our resources once we conclude work on a feature branch is equally crucial. Utilizing CloudFormation for our infrastructure simplifies this process, as it involves merely deleting the designated stack. Nevertheless, certain supplementary measures are required if resources like S3 buckets or ECRs are established within these stacks, as they necessitate prior emptying. In our particular situation, we employ a scheduled vacuum job that examines all present dynamic stacks lacking an affiliated feature branch in GITLAB. This task is responsible for eliminating these stacks.
Having this kind of setup in our way of working gave us a few noticeable advantages.
• Increased reliability
When each developer has their dedicated development resources operational in the cloud, tasks in the development process are expedited, and a stronger sense of reliability is achieved. The need to be cautious about others’ code overwriting due to their pushes in the cloud is eliminated for every developer.
• Isolated E2E testing and R&D
As each dynamically generated stack mirrors our production setup, we possess the flexibility to conduct swift end-to-end tests on our personal branches or engage in research and development tasks. For instance, if there’s a necessity to contrast two distinct iterations of the same module, we can effortlessly push two separate branches in GIT. This action will trigger the creation of two entirely separate environments, enabling us to carry out our testing procedures.
• Development speed
We’ve witnessed an uptick in our development pace and deployment speed. Developers no longer have to wait for their colleagues working on the same module to finish their tasks and testing in the DEV environment.
The convenience and reliability of this setup have greatly improved our work process, and there’s no turning back from it now. While our Continuous Integration/Continuous Deployment (CICD) pipeline and tasks are still in the process of refinement, we have plans to expand our approach further by incorporating a hybrid cloud environment. For instance, in our specific case, we’ve also adapted our Snowflake design architecture using Terraform to align it with this branch-oriented deployment strategy.
I hope these insights have proven beneficial. From my perspective, the advantages are quite apparent. We've greatly enhanced our ability to replicate, test, and troubleshoot production-related issues within our DEV environment, leading to a more robust development process. Our decision to integrate Infrastructure as Code (IaC) with our codebase, versioning it in Gitlab, has empowered us to swiftly recreate precise cloud environment configurations as needed, fostering efficiency and consistency.
Perhaps most satisfying of all is the noticeable acceleration and increased reliability in our day-to-day work. Knowing that changes won't inadvertently disrupt each other's changes in DEV environment provides peace of mind and enables us to focus on our tasks with confidence and efficiency.
//Shubhomoy